RGB-D Salient Object Detection with Cross-Modality Modulation and Selection
2 Beijing Jiaotong University, Beijing, China
3 Dalian University of Technology, Dalian, China
4 Chinese Academy of Sciences, Beijing, China
Abstract
We present an effective method to progressively integrate and refine the cross-modality complementarities for RGB-D salient object detection (SOD). The proposed network mainly solves two challenging issues: 1) how to effectively integrate the complementary information from RGB image and its corresponding depth map, and 2) how to adaptively select more saliency-related features. First, we propose a cross-modality feature modulation (cmFM) module to enhance feature representations by taking the depth features as prior, which elaborately models the complementary relations of RGB-D data. Second, we propose an adaptive feature selection (AFS) module to gradually select saliency-related features and suppress the inferior ones. The AFS module exploits multi-modality spatial feature fusion with the self-modality and cross-modality interdependencies of channel features are considered. Third, we employ a saliency-guided position-edge attention (sg-PEA) module to encourage our network to focus more on saliency-related regions. The above modules as a whole, called cmMS block, facilitates the refinement of saliency features in a coarse-to-fine fashion. Coupled with a bottom-up inference, the refined saliency features enable accurate and edge-preserving SOD. Extensive experiments demonstrate that our network outperforms state-of-the-art saliency detectors on six popular RGB-D SOD benchmarks.
Pipeline
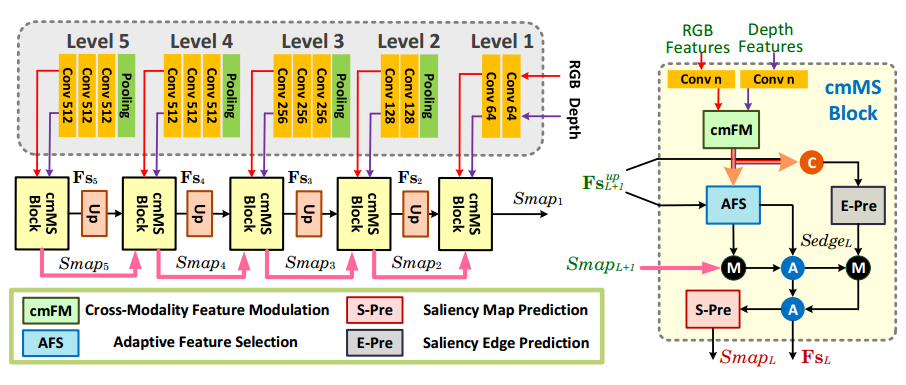
a cross-modality feature modulation module that enhances RGB feature representations by taking the corresponding depth features as prior;
an adaptive feature selection module that progressively emphasizes the importance of channel features in self- and cross-modalities while fusing the significant multi-modality spatial features
Highlights
Results
1. Visual Comparisons


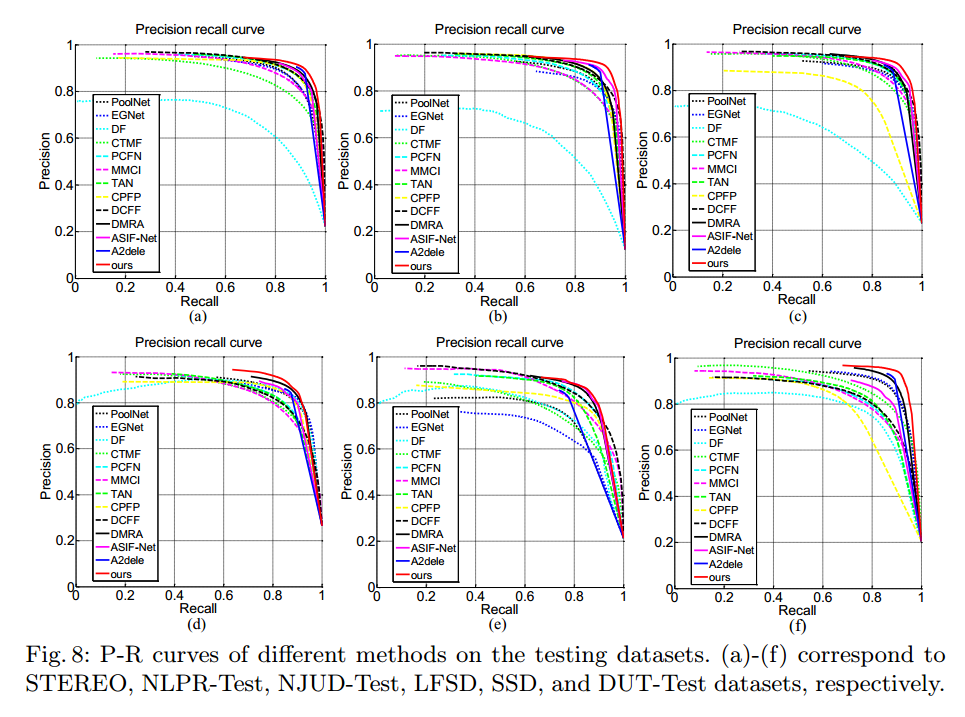
2. P-R Curves
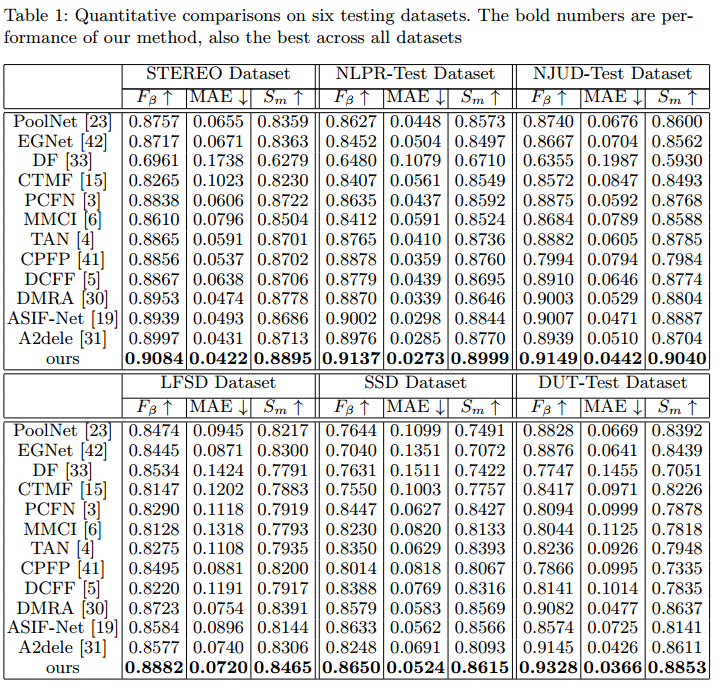
3. Quantitative Results
Materials
|
Paper |
Supplementary Material |
Code and Model |
Citation
@Article{li2020,
author = {Li, Chongyi and Cong, Runmin and Piao, Yongri and Xu, Qianqian and Loy, Chen Change},
title = {RGB-D salient object eetection with cross-modality modulation and selection},
journal = {ECCV},
pape={},
year = {2020}
}
Contact
If you have any questions, please contact Chongyi Li at lichongyi25@gmail.com.