BeautyREC:
Robust,
Efficient, and
Component-Specific,
Makeup Transfer

Abstract
In this work, we propose a Robust, Efficient, and Component-specific makeup transfer method (abbreviated as BeautyREC). A unique departure from prior methods that leverage global attention, simply concatenate features, or implicitly manipulate features in latent space, we propose a component-specific correspondence to directly transfer the makeup style of a reference image to the corresponding components (e.g., skin, lips, eyes) of a source image, making elaborate and accurate local makeup transfer. As an auxiliary, the long-range visual dependencies of Transformer are introduced for effective global makeup transfer. Instead of the commonly used cycle structure that is complex and unstable, we employ a content consistency loss coupled with a content encoder to implement efficient single-path makeup transfer. The key insights of this study are modeling component-specific correspondence for local makeup transfer, capturing long-range dependencies for global makeup transfer, and enabling efficient makeup transfer via a single-path structure.
We also contribute \textbf{BeautyFace}, a makeup transfer dataset to supplement existing datasets. This dataset contains 3,000 faces, covering more diverse makeup styles, face poses, and races. Each face has annotated parsing map. Extensive experiments demonstrate the effectiveness of our method against state-of-the-art methods. Besides, our method is appealing as it is with only 1M parameters, outperforming the state-of-the-art methods (BeautyGAN: 8.43M, PSGAN: 12.62M, SCGAN: 15.30M, CPM: 9.24M, SSAT: 10.48M).
Method
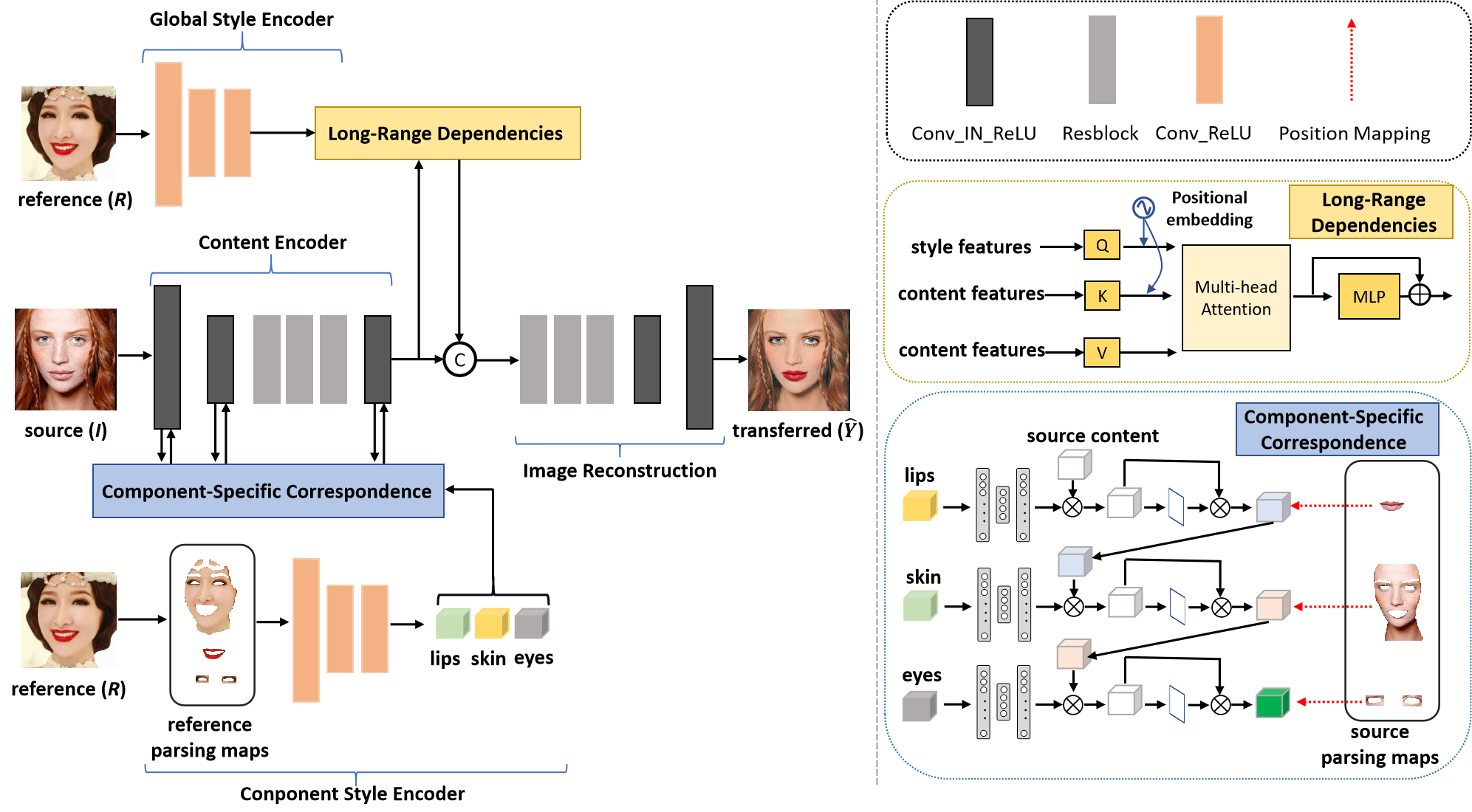
It consists of a content encoder, a component style encoder, a global style encoder, a component-specific correspondence, a long-range dependency, and an image reconstruction. Note that the skip-connections between the content encoder and image reconstruction are removed in figure for brevity.
Dataset

It contains 3,000 high-quality face images with a higher resolution of 512*512, covering more recent makeup styles and more diverse face poses, backgrounds, expressions, races, illumination, etc. Besides, we annotate each face with parsing, which benefits more diverse applications.
Video Demo
The results are achieved by our BeautyREC with only 1M parameters.

Citation
If you find our dataset and paper useful for your research, please consider citing our work:
@inproceedings{BeautyREC,
author = {Yan, Qixin and Guo, Chunle and Zhao, Jixin and Dai, Yuekun and Loy, Chen Change and Li, Chongyi},
title = {BeautyREC: Robust, Efficient, and Component-Specific Makeup Transfer},
booktitle = {Arixv},
year = {2022}
}
License
We retain all the copyrights of this method.
Contact
If you have any question, please contact us via qixinyan@tencent.com or lichongyi25@gmail.com.