CuDi:
Curve
Distillation for Efficient and
Controllable Exposure Adjustment

Abstract
We present Curve Distillation, CuDi, for efficient and controllable exposure adjustment without the requirement of paired or unpaired data during training. Our method inherits the zero-reference learning and curve-based framework from an effective low-light image enhancement method, Zero-DCE, with further speed up in its inference speed, reduction in its model size, and extension to controllable exposure adjustment. The improved inference speed and lightweight model are achieved through novel curve distillation that approximates the time-consuming iterative operation in the conventional curve-based framework by high-order curve's tangent line. The controllable exposure adjustment is made possible with a new self-supervised spatial exposure control loss that constrains the exposure levels of different spatial regions of the output to be close to the brightness distribution of an exposure map serving as an input condition. Different from most existing methods that can only correct either underexposed or overexposed photos, our approach corrects both underexposed and overexposed photos with a single model. Notably, our approach can additionally adjust the exposure levels of a photo globally or locally with the guidance of an input condition exposure map, which can be pre-defined or manually set in the inference stage. Through extensive experiments, we show that our method is appealing for its fast, robust, and flexible performance, outperforming state-of-the-art methods in real scenes.
Method
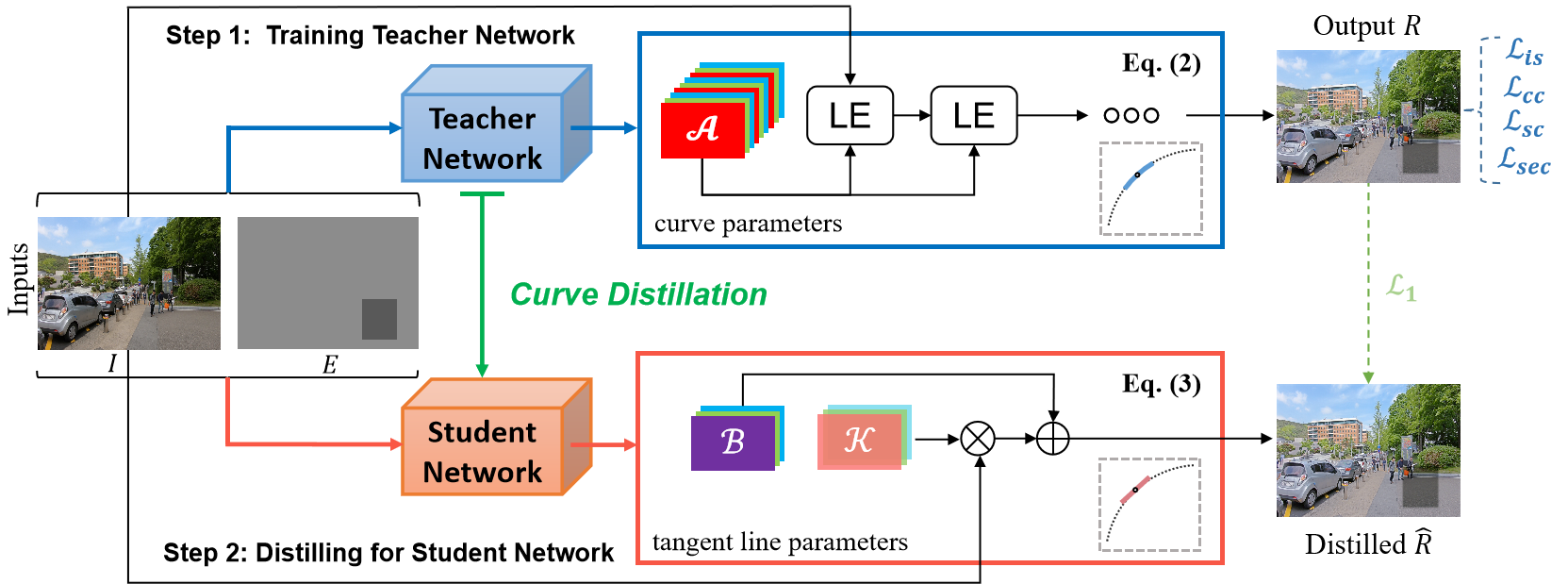
Our framework consists of two steps: Step 1: Training Teacher Network; Step 2: Distilling for Student Network. Given an image $I$ and a condition exposure map $E$ that is (set randomly in the training stage; pre-defined or manually set in the inference stage), we feed the two inputs to a teacher network to estimate the parameters ($\mathcal{A}$) of quadratic curves $\text{LE}$ that are iteratively applied for obtaining a high-order curve. The high-order curve can map the input image $I$ to the output $R$. A set of zero-reference losses is used to train the teacher network. After training the teacher network, we fix its weights then distill for a lightweight student network. The two inputs are simulatenously fed to the teacher network and the student network. Taking the high-order curve's output $R$ as supervision, the student network estimates the parameters (slope map: $\mathcal{K}$ and intercept map: $\mathcal{B}$) of the high-order curve's tangent line. Then, the tangent line can map the input image $I$ to the distilled $\hat{R}$ that approximates the output $R$ of the high-order curve. \textit{After curve distillation, we only use the distilled student network in the inference stage.
Diverse results on real-world exposure scenes.
The results are achieved by a single zero-reference learning-based model CuDi with only 3K parameters.
(DownloadVideo)

Citation
If you find our dataset and paper useful for your research, please consider citing our work:
@inproceedings{Li2022cudi,
author = {Li, Chongyi and Guo, Chunle and Feng, Ruicheng and Zhou, Shangchen and Loy, Chen Change},
title = {CuDi: Curve Distillation for Efficient and Controllable Exposure Adjustment},
booktitle = {arXiv:2207.14273},
year = {2022}
}
License
We retain all the copyrights of this method.
Contact
If you have any question, please contact us via lichongyi25@gmail.com.